適当なお題でコードを書いてみて、基本的な構文やライブラリの使い方を把握します。
今回は「にゃんこ大戦争」のキャラクタデータを可視化します。
元データ取得
メインロジック
解析対象のデータはにゃんこ大戦争データベースのものを使わせていただきました。
ライブラリは、Webからのデータ取得にはRequestsを、取得したHTMLの解析にはBeautifulSoupを使います。
import requests
import bs4
# リクエスト発行
response = requests.get('https://battlecats-db.com/unit/status_r_all.html')
# レスポンス解析
soup = bs4.BeautifulSoup(response.text)キャラクタデータ抽出
メインロジック
キャラクタデータはHTMLのtableに格納されています。
tableタグにはID属性にListという名前がついているため、これを使いつつ、trタグのデータをリストとして取得します。
各セルのデータはtdタグから取得しますが、td内はセル毎に構造が異なるため、列ごとに取得方法を変えつつ、行に見立てたキャラクタデータオブジェクト(=data)に値を突っ込みます。
obj_list = [] # 行データの格納用リスト
tr_list = soup.select('#List tbody tr')
for tr in tr_list:
data = {} # 行データ用オブジェクト
td_list = tr.find_all('td')
data['no'] = td_list[0].text
data['rank'] = td_list[1].find('font').find('a').text
data['name'] = get_text(td_list[3], 'a')
font_list = td_list[4].find_all('font')
data['level'] = font_list[0].text
data['ex_level'] = font_list[1].text
data['hp'] = get_text(td_list[5], 'font')
data['kb'] = get_text(td_list[6], 'font')
data['speed'] = get_text(td_list[7], 'font')
data['attack'] = get_text(td_list[8], 'font')
data['dps'] = get_text(td_list[9], 'font')
data['target'] = get_text(td_list[10], 'font')
data['frequency'] = get_text(td_list[11], 'font')
data['occurrence'] = get_text(td_list[12], 'font')
data['effective_range'] = get_text(td_list[13], 'font')
data['cost'] = get_text(td_list[14], 'font')
data['production'] = get_text(td_list[15], 'font')
data['top_level'] = ('最上位形態' in td_list[16].find('font', class_='kensakuyou').text)
obj_list.append(data)関数(配下のタグ有無吸収)
少し楽をするため、解析対象オブジェクト配下にタグがあったりなかったりする差異を吸収する関数を作ります。タグがあればタグ内のテキストを、なければ直下のテキストを返却します。
def get_text(td, tag_name):
tmp = td.find(tag_name)
return tmp.text if type(tmp) == bs4.element.Tag else td.text実行結果
できたキャラクタデータオブジェクトはこんな感じです。
obj_list
[{'no': '001-1',
'rank': '基本',
'name': 'ネコ',
'level': '20',
'ex_level': '80',
'hp': '4,200',
'kb': '3',
'speed': '10',
'attack': '335',
'dps': '272',
'target': '単体',
'frequency': '37',
'occurrence': '8',
'effective_range': '140',
'cost': '75',
'production': '60',
'top_level': False},
・
・
・可視化
可視化は軸を変えて何度も実行すると想定されるため関数化します。
メイン関数
元データ、X軸データのキー名、Y軸データのキー名、フィルタ条件を受け取り、散布図と近似直線のグラフデータを返却する関数を作ります。
大抵のゲームでは、キャラクタのレア度毎に総合的なステータスが異なるので、可視化の際に色分けされるようにします。
なお、グラフ描画にはmatplotlib.pyplotを使用します。
import matplotlib.pyplot as plt
def plot_data(obj_list, x_label, y_label, filter_dict):
# 描画エリア作成
fig = plt.figure(figsize=(8, 5), dpi=150)
ax = fig.add_subplot(1,1,1)
# パラメータ生成
params = [{'rank':'伝説レア', 'color':'black', 'label':'UR'}
,{'rank':'超激レア', 'color':'red', 'label':'SSR'}
,{'rank':'激レア', 'color':'pink', 'label':'SR'}
,{'rank':'レア', 'color':'yellow', 'label':'R'}
,{'rank':'EX', 'color':'green', 'label':'EX'}
,{'rank':'基本', 'color':'blue', 'label':'N'}]
for p in params:
# フィルタ用辞書更新
custom_filter_dict = {'rank':p['rank']}
custom_filter_dict.update(filter_dict)
# 描画データ作成
p['x'], p['y'] = create_plot_data(obj_list, x_label, y_label, custom_filter_dict)
# 散布図プロット
ax.scatter(p['x'], p['y'], color=p['color'], alpha=0.5, linewidths='1', label=p['label'])
# 描画範囲取得
left, right = ax.get_xlim()
bottom, top = ax.get_ylim()
for p in params:
# 近似直線データ作成
x, y = create_regression_line(p['x'], p['y'], left, right)
# 近似直線プロット
ax.plot(x, y, color=p['color'])
# 各種描画設定
ax.set_title(str(filter_dict))
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
ax.set_ylim(-1 * top/10, top)
ax.grid(True)
ax.legend(loc='upper left')
return figサブ関数(散布図用データの抽出および生成)
キャラクタデータ群から目的のデータを抽出し、X軸データリストとY軸データリストを返却する関数を作成します。各軸用のデータは数値である必要があるため、カンマの除去やハイフンの置換をしたうえで数値型への変換を行います。
抽出条件は。filter_dictの全てのKEY/VALUEに対して、obj_list[KEY] == VALUEが成立していることです。
from functools import reduce
def create_plot_data(obj_list, x_label, y_label, filter_dict):
obj_filtered_list = list(filter(lambda obj: reduce(lambda l, x:l & (obj[x[0]] == x[1]), filter_dict.items(), True), obj_list))
x = list(int(o[x_label].replace(',', '').replace('-', '0')) for o in obj_filtered_list)
y = list(int(o[y_label].replace(',', '').replace('-', '0')) for o in obj_filtered_list)
return x, yサブ関数(近似直線用データ生成)
近似直線用データを生成する関数を作成します。
近似直線の計算にはNumPy.polyfitを使用します。
近似直線のX軸データとして散布図用のxを使うと、X軸描画範囲が散布図データの存在する範囲に限定されてしまうため、描画エリア情報から取得した値(left,right)を使ってX軸用データを生成します。
import numpy as np
def create_regression_line(x, y, left, right, deg=1):
p = np.polyfit(x, y, deg) # 近似式の係数を算出
f = np.poly1d(p) # 近似式のモデルを生成
xp = np.linspace(left, right, 100) # X軸用データの生成
return xp, f(xp)実行結果
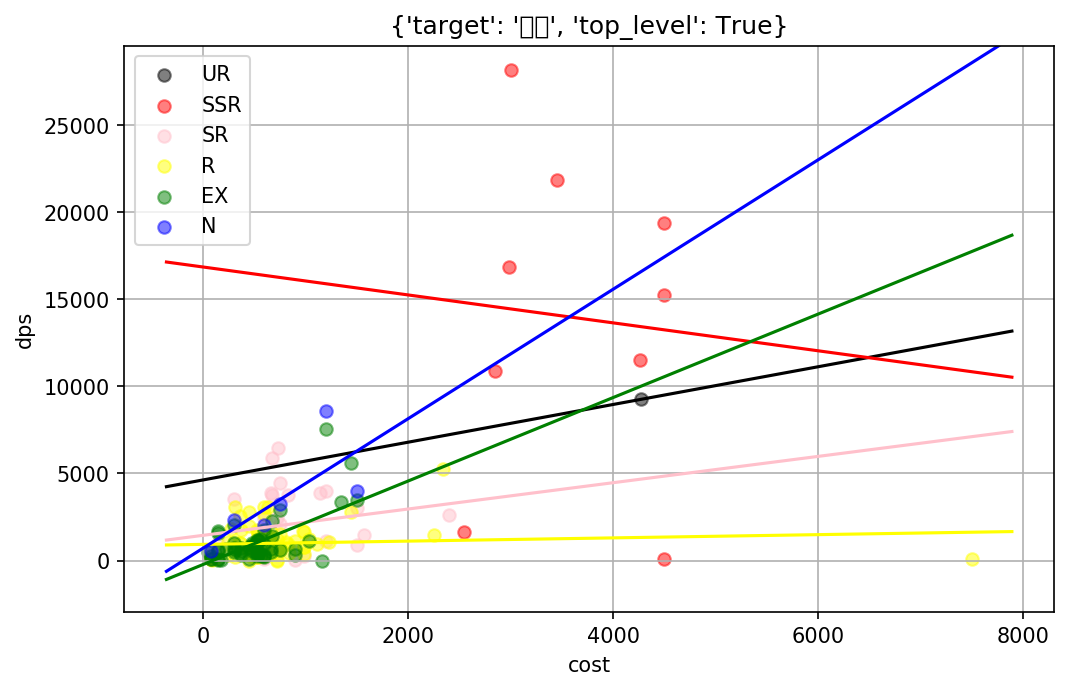
範囲攻撃キャラのコストとDPSをプロットするとこんな感じになります。
fig = plot_data(obj_list, 'cost', 'dps', {'target':'範囲', 'top_level':True})
fig.show()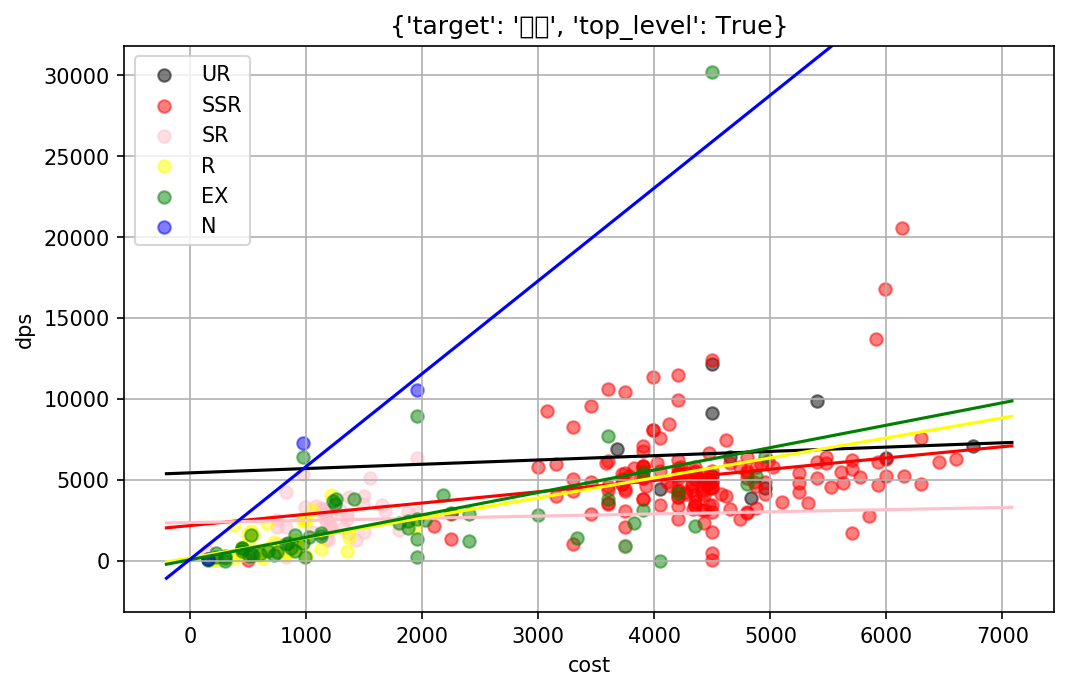
単体攻撃キャラだとこんな感じです。
fig = plot_data(obj_list, 'cost', 'dps', {'target':'単体', 'top_level':True})
fig.show()